Not all LLMs are equal when it comes to security analysis. We ran the numbers.
As Corefix integrates AI into its vulnerability management pipeline, we needed to answer a deceptively simple question: which models actually perform well on real-world security analysis tasks?
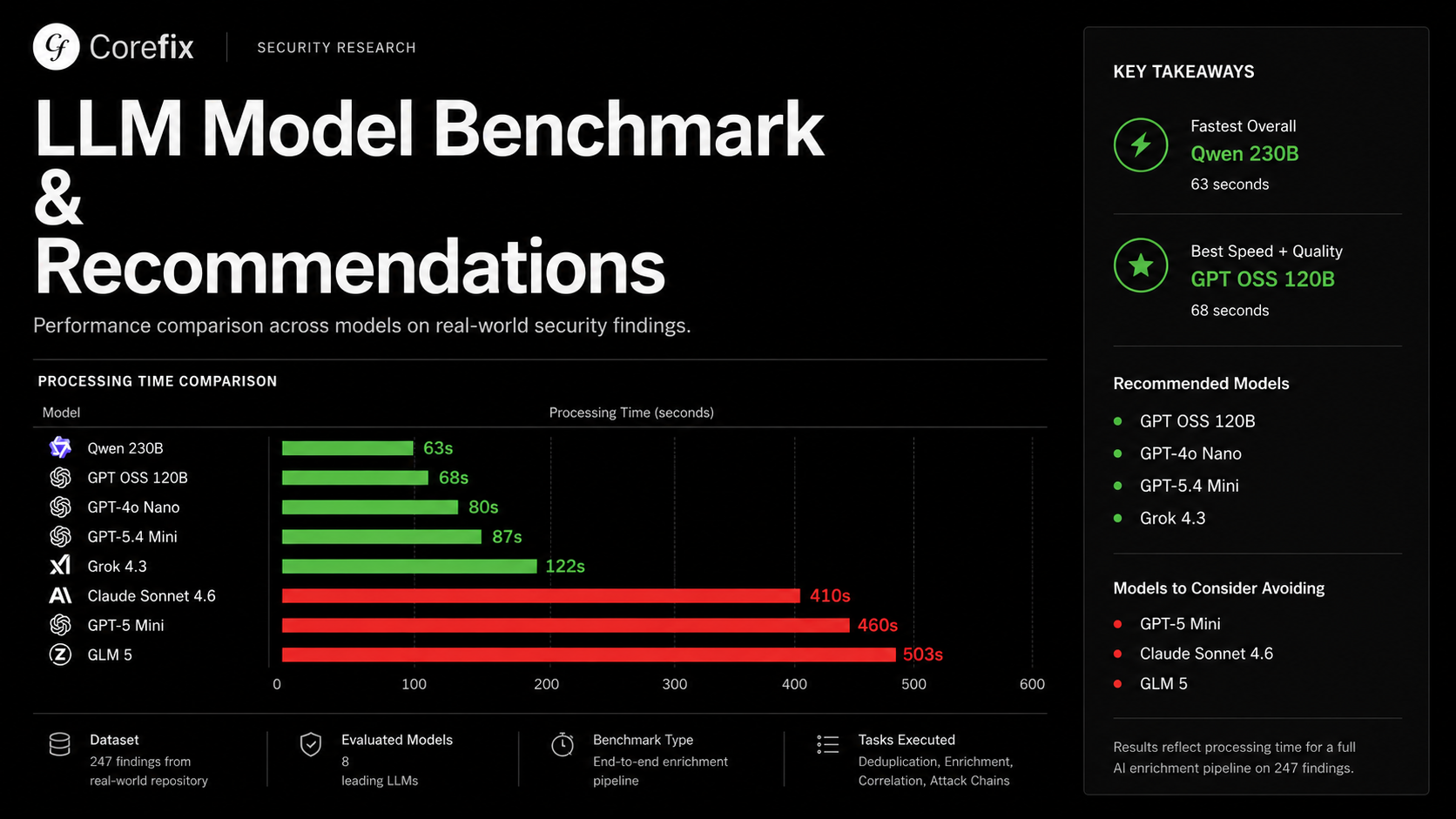
We ran a systematic benchmark against the chef repository — a forked version of the original Chef project, approximately 2000 commits behind upstream — producing 247 findings across secrets, dependency vulnerabilities, Semgrep findings, and IaC findings. We fed these through our full AI enrichment pipeline across 21 models and measured what happened.
The results were not what we expected.
What We Tested
Every model ran the same four-task pipeline against the complete 247-finding dataset:
- Deduplication: collapsing duplicate findings across scanners
- Enrichment: adding context, severity reasoning, and remediation guidance to each finding
- Cross-scanner correlation: linking related findings from different tools — for example, a secret finding correlating with a dependency vulnerability in the same service
- Attack chain identification: identifying sequences of findings that could be chained into an exploitable attack path
Processing time reflects how long each model took to complete the full pipeline on the 247-finding dataset. This is initial benchmarking — results will vary as prompts and pipeline logic are refined.
Processing Time Results
| Model | Provider | Processing Time | Notes |
|---|---|---|---|
| Haiku | Claude | 108s | — |
| Sonnet 4.6 | Claude | 410s | Slowest Claude variant tested |
| GLM 4.7 | Zhihu AI | 153s | — |
| Grok 4.3 | xAI | 122s | — |
| Bedrock Minimax 2.5 | AWS Bedrock | 168s | — |
| Bedrock Kimi K2.5 | AWS Bedrock | 143s | — |
| Bedrock GLM-4.7-Flash | AWS Bedrock | 143s | Faster flash variant |
| Bedrock GLM 5 | AWS Bedrock | 503s | Slowest overall |
| Bedrock DeepSeek 3.2 | AWS Bedrock | 248s | — |
| Bedrock Qwen 230B | AWS Bedrock | 63s | Fastest; attack chains not found |
| Bedrock GPT OSS 120B | AWS Bedrock | 68s | Worked well |
| GPT-5.4 | OpenAI | 226s | — |
| GPT-5.4 Mini | OpenAI | 87s | Good speed |
| GPT-5.4 Nano | OpenAI | 117s | — |
| GPT-4.1 Mini | OpenAI | 118s | — |
| GPT-4o Nano | OpenAI | 80s | Very fast |
| GPT-5 Mini | OpenAI | 460s | Unexpectedly slow |
| GPT-5 Nano | OpenAI | 380s | Slow for nano tier |
| GPT-5 | OpenAI | 410s | — |
| GPT-5.1 | OpenAI | 140s | Balanced |
| GPT-5.2 | OpenAI | 248s | — |
Key Observations
The spread is wider than expected across all tiers:
- Fastest overall: Bedrock Qwen 230B at 63 seconds — but attack chain identification was absent from results
- Best speed and quality balance: Bedrock GPT OSS 120B at 68 seconds, with strong overall task completion
- Fast OpenAI options: GPT-4o Nano at 80 seconds, GPT-5.4 Mini at 87 seconds
- Slowest models: Bedrock GLM 5 at 503 seconds, GPT-5 Mini at 460 seconds, Claude Sonnet 4.6 at 410 seconds
The counterintuitive finding: model size does not predict processing time. GPT-5 Mini (460s) is nearly as slow as full GPT-5 (410s) and significantly slower than GPT-5.4 (226s). Nano tiers cluster between 80–380 seconds — a 4x range that reflects rate limiting and infrastructure variance as much as model capability.
Recommendations and Known Issues
Based on testing across all providers, here is what we found:
Kimi Do not use kimi-k2.5 or kimi-2.6 directly via their API — they are being overloaded or rate-limited despite Tier 1 access. Use k2.5 via AWS Bedrock instead.
GLM Models All direct GLM model calls are resulting in 429 or 524 errors. Avoid calling GLM models directly. Use Bedrock for GLM 5, GLM 4.7, and GLM 4.7-Flash. Note that GLM 4.7 can be used for coding tasks but concurrency is limited to 1.
Claude on Bedrock Bedrock Anthropic Haiku is working, but the model must be activated via AWS with a support ticket specifying your use case before it can be used.
JSON Response Format GPT OSS 120B and Claude APIs do not support type: json_object as a response format. If jsonFormat=false, add explicit JSON formatting rules to the system prompt. The custom JSON parser will handle extracting structured output from the model response.
GPT Models All GPT models including nano and mini variants are working. Previous issues with nano and mini variants are resolved.
Context and Token Limits No context-related issues or max token errors observed — everything appears stable on this front.
Why We Built Corefix
AI-assisted security analysis is only as good as the pipeline surrounding the model. Raw processing time is one dimension — but attack chain identification, cross-scanner correlation, and enrichment quality all depend on how findings are assembled and presented before the model ever sees them.
Corefix wraps model selection with full context assembly. Every finding gets the surrounding code, dependency context, framework version, and scanner evidence before the LLM processes it. We run this pipeline across all major providers — Bedrock, OpenAI, Anthropic direct — and select the optimal model per task type based on benchmarks like these.
The practical result: you don't choose a model or write prompt templates. Corefix handles selection, context assembly, and quality control. You get enriched findings with remediation guidance, deduplicated across scanners, with attack chains identified automatically.
What took us weeks of benchmarking to determine, Corefix handles on every scan.
Corefix integrates AI enrichment across all major models and providers. Try a free scan → to see AI-powered security analysis on your actual findings.